Relational Databases (RDBMS) have been the de facto standard for storing information for fairly significant period of time, almost since the dawn of the Information Technology Industry. For software developers, traditionally, the obvious choice has been RDBMS and most of us really never gave any serious thought for storing data in any other format. But that's not the case anymore, now the developers are spoilt for choice. In last decade, many new offerings came out of the Labs of Google, Amazon, Facebook, Apache foundation & many niche DB Vendors. They are now mature with proven track records and challenging the dominance of Relation Databases. Yes, I am referring the new generation of Databases i.e. NoSQL Databases (also known as Schemaless Databases), In-memory Data stores and what they call New SQL Databases.
In this post, I will introduce the broad categories of NoSQL databases & various offerings under each category, a brief mention of various drivers behind this movement, cover few use cases where NoSQL databases will score better than the regular RDBMS databases and finally what you give up when you gain so much. What I don't intend to cover here is a detailed technical explanation of key concepts like ACID, BASE, CAP Theorem or details on sharding, partitioning, replication, map-reduce and other associated technological concepts. I do have a plan to cover them in a separate blog post.

A graph database is a database that uses graph structures with nodes, edges, and properties to represent and store data. A graph database is any storage system that provides index-free adjacency. This means that every element contains a direct pointer to its adjacent elements and no index lookups are necessary.
Wide-Column Stores are derived from Google's BigTable. BigTable is a compressed, high performance, and proprietary data storage system built on Google File System. BigTable maps two arbitrary string values (row key and column key) and timestamp (hence three dimensional mapping) into an associated arbitrary byte array. It is not a relational database and can be better defined as a sparse, distributed multi-dimensional sorted map. BigTable is designed to scale into the petabyte range across hundreds or thousands of machines. Every row can have it's set of columns.
A New SQL Database - Simply put it's Scalable RDBMS.
Note above definitions are summed up from various sources.
Key-Value Stores: Redis, Riak, DynamoDB, Voldemort
Wide-Column Stores: BigTable (Internal to Google, partially available via AppStore), Cassandra, HBase
Document Stores: MongoDB, Couchbase, CouchDB, SimpleDB
Graph Databases: Neo4j, InfiniteGraph, FlockDB
Although the following lists are not part of NoSQL family but they are still very relevant and significant, hence mentioning few examples -
In-Memory Stores (Key-Value): memcached, Ehcache
New SQL Databases: VoltDB, Amazon RDS, NuoDB, MySQL Cluster, Clustrix
And for old time's sake -
Relational Databases: Maria DB, MySQL, Microsoft-SQL, IBM DB2, Oracle.
As you see the list is pretty long and at times, it may be slightly confusing as well. In the lists above, the products are grouped under a specific category based on what they claim or their dominant characteristics. But there could be instances where some of the offerings may overlap into two different categories.
Here is nice infographics grouping different offerings under different categories published by Matthew Aslett in his blog.

Scalability: With the advent of consumer Internet and massive penetration on mobile devices, scalability challenges increased exponentially. Answer to this challenge was to go for Scale-out architecture (horizontal scaling) over Scale-up (vertical scaling). Traditional RDBMS offerings either failed to adopt the scale-out architecture or they became too complex to manage at that scale. NoSQL databases, particularly Key-Value Pair Databases and Wide Column Stores or Column family Databases came to the rescue. Some of the shining examples would include Google's BigTable and others in it's family (e.g. HBase, Cassandra etc), Amzaon's DynamoDB or other key-value stores like Redis, Riak and finally in memory caches like Memcached etc.
Here is a slide from Emil Eifrem's presentation that shows how various types of DBs are stacked up when it comes to scaling etc.

Schemaless Databases: Scalability was one major reason why companies experiencing Web Scale traffic started looking beyond RDMBS, but a large section of developers started adopting NoSQL Databases for their flexibility. Document databases with their ability to store as well as query JSON/BSON data became popular among the developers. It would be a nightmare to store data like Blogposts, Comments, nested comments etc using a traditional RDBMS and more so as those structures keep on changing. Lot of time, particularly in case of configuration data, each record may have different attributes. Using regular RDBMS databases managing such use cases become very messy - typically for a single such record there will be as many name value pairs entries as the number of attributes or one large table with all possible columns and each record will make use of a fraction of those columns. It becomes quite messy in terms of reading, writing and maintainability point of view. However, Document Databases and Wide Column Databases will work just perfect in these usecases. Unlike traditional RDBMS Databases, Schemaless databases keep related information together and avoid joins.
Economics: Third major reason lies in the economics around capacity building. Unlike large enterprises where they can forecast the future capacity requirements as well as have deep pocket to finance the large servers upfront, start-ups really don't know whether they would be successful enough to invest in large servers coupled with the fact that capital is far more scarce resource in the star-up world. So, upfront investment on large servers becomes a very difficult proposition & a huge entry barrier. They really needed a way to add capacity as they move on (& as far as they move on) and without impacting existing services. The architectures proposed by Amazon's Dynamo DB and Google's BigTable came to the relief. Scale-out architecture took over Scale-up architecture enabling companies to add capacity as they need them & allowing them to grow infinitely. This reduced the need for upfront capital requirement and lowered the entry barrier.
Graph Database: Need for Graph databases is distinctly different from others and represents the real world problem as they appear. In real world everything in interconnected either directly or through others. Graph represents all those connected entities as "nodes" and the connections as "relationship". It can help answer questions like "How do I reach New York?" or "How am I connected to Matt?" or "What movie Julie may like to watch?". Traditional databases fail to scale as the relationships become deeper. Large Social Network sites like Facebook, Linkedin, Twitter have their own graph database implementation and there are few commercially available Graph databases for everyone's use. However, Graph databases are not as scalable as other families of NoSQL databases.
One of the points I did not highlight here is "availability", that's really not a point of differentiation anymore rather a point of parity and most of the RDBMS vendors as well as NoSQL databases provide high availability through replication and fail over.
To put the things in perspective, take a look at the projected revenue growth for various categories as per a study done by the 451 group

Connect to me on twitter @satya_paul
Check out my storyboard on www.fanffair.com - http://www.fanffair.com/storyboard/satyajitp2011
In this post, I will introduce the broad categories of NoSQL databases & various offerings under each category, a brief mention of various drivers behind this movement, cover few use cases where NoSQL databases will score better than the regular RDBMS databases and finally what you give up when you gain so much. What I don't intend to cover here is a detailed technical explanation of key concepts like ACID, BASE, CAP Theorem or details on sharding, partitioning, replication, map-reduce and other associated technological concepts. I do have a plan to cover them in a separate blog post.
Broad Classification of NoSQL Databases
NoSql or Schemaless Databases can broadly be categorized as following:
A key-value store: it's a storage system that stores values indexed by a key. Typically, you can query only by the key and values are opaque and can not be used for querying. This allows very fast read and write operations (a simple disk access) and this model is seen as a kind of non volatile cache (i.e. well suited if you need fast accesses by key to long-lived data). This category of databases are largely inspired by a paper by Amazon based on DynomoDB.

A document-oriented database extends the previous model and values are stored in a structured format (a document, hence the name) that the database can understand. For example, a document could be a blog post and the comments and the tags stored in a denormalized way. Since the data are transparent, the store can do more work (like indexing fields of the document) and you're not limited to query only by key. IBM's Lotus Notes Database has largely influenced this category of databases.
A document-oriented database extends the previous model and values are stored in a structured format (a document, hence the name) that the database can understand. For example, a document could be a blog post and the comments and the tags stored in a denormalized way. Since the data are transparent, the store can do more work (like indexing fields of the document) and you're not limited to query only by key. IBM's Lotus Notes Database has largely influenced this category of databases.
A graph database is a database that uses graph structures with nodes, edges, and properties to represent and store data. A graph database is any storage system that provides index-free adjacency. This means that every element contains a direct pointer to its adjacent elements and no index lookups are necessary.
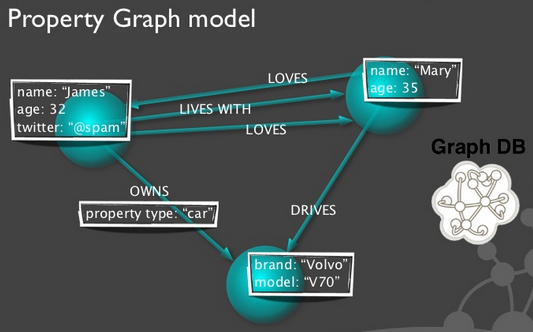 |
| Source: Presentation by Emil Eifrem, CEO of neo4j |
 |
| Paper by Kai Orend |
A New SQL Database - Simply put it's Scalable RDBMS.
Note above definitions are summed up from various sources.
Examples of NoSQL Databases
Here are few examples from each of them, I tried to pick the popular ones from each category.Wide-Column Stores: BigTable (Internal to Google, partially available via AppStore), Cassandra, HBase
Document Stores: MongoDB, Couchbase, CouchDB, SimpleDB
Graph Databases: Neo4j, InfiniteGraph, FlockDB
Although the following lists are not part of NoSQL family but they are still very relevant and significant, hence mentioning few examples -
In-Memory Stores (Key-Value): memcached, Ehcache
New SQL Databases: VoltDB, Amazon RDS, NuoDB, MySQL Cluster, Clustrix
And for old time's sake -
Relational Databases: Maria DB, MySQL, Microsoft-SQL, IBM DB2, Oracle.
As you see the list is pretty long and at times, it may be slightly confusing as well. In the lists above, the products are grouped under a specific category based on what they claim or their dominant characteristics. But there could be instances where some of the offerings may overlap into two different categories.
Here is nice infographics grouping different offerings under different categories published by Matthew Aslett in his blog.
Usecases and Drivers behind the adoption of NoSQL Databases
Here are few drivers and usecases that drove the adoption of NoSQL databases.Scalability: With the advent of consumer Internet and massive penetration on mobile devices, scalability challenges increased exponentially. Answer to this challenge was to go for Scale-out architecture (horizontal scaling) over Scale-up (vertical scaling). Traditional RDBMS offerings either failed to adopt the scale-out architecture or they became too complex to manage at that scale. NoSQL databases, particularly Key-Value Pair Databases and Wide Column Stores or Column family Databases came to the rescue. Some of the shining examples would include Google's BigTable and others in it's family (e.g. HBase, Cassandra etc), Amzaon's DynamoDB or other key-value stores like Redis, Riak and finally in memory caches like Memcached etc.
Here is a slide from Emil Eifrem's presentation that shows how various types of DBs are stacked up when it comes to scaling etc.
Schemaless Databases: Scalability was one major reason why companies experiencing Web Scale traffic started looking beyond RDMBS, but a large section of developers started adopting NoSQL Databases for their flexibility. Document databases with their ability to store as well as query JSON/BSON data became popular among the developers. It would be a nightmare to store data like Blogposts, Comments, nested comments etc using a traditional RDBMS and more so as those structures keep on changing. Lot of time, particularly in case of configuration data, each record may have different attributes. Using regular RDBMS databases managing such use cases become very messy - typically for a single such record there will be as many name value pairs entries as the number of attributes or one large table with all possible columns and each record will make use of a fraction of those columns. It becomes quite messy in terms of reading, writing and maintainability point of view. However, Document Databases and Wide Column Databases will work just perfect in these usecases. Unlike traditional RDBMS Databases, Schemaless databases keep related information together and avoid joins.
Economics: Third major reason lies in the economics around capacity building. Unlike large enterprises where they can forecast the future capacity requirements as well as have deep pocket to finance the large servers upfront, start-ups really don't know whether they would be successful enough to invest in large servers coupled with the fact that capital is far more scarce resource in the star-up world. So, upfront investment on large servers becomes a very difficult proposition & a huge entry barrier. They really needed a way to add capacity as they move on (& as far as they move on) and without impacting existing services. The architectures proposed by Amazon's Dynamo DB and Google's BigTable came to the relief. Scale-out architecture took over Scale-up architecture enabling companies to add capacity as they need them & allowing them to grow infinitely. This reduced the need for upfront capital requirement and lowered the entry barrier.
Graph Database: Need for Graph databases is distinctly different from others and represents the real world problem as they appear. In real world everything in interconnected either directly or through others. Graph represents all those connected entities as "nodes" and the connections as "relationship". It can help answer questions like "How do I reach New York?" or "How am I connected to Matt?" or "What movie Julie may like to watch?". Traditional databases fail to scale as the relationships become deeper. Large Social Network sites like Facebook, Linkedin, Twitter have their own graph database implementation and there are few commercially available Graph databases for everyone's use. However, Graph databases are not as scalable as other families of NoSQL databases.
One of the points I did not highlight here is "availability", that's really not a point of differentiation anymore rather a point of parity and most of the RDBMS vendors as well as NoSQL databases provide high availability through replication and fail over.
Conclusion
As you start benefiting from some of the NoSQL features, you must be aware of the areas where you have to give up. Here is short list of areas where you may have to do compromises:- Accepting Eventual Consistency over transaction level consistency (ACID)
- Increased Complexity: Organizing data in a way that all related information remain under one sharded node.
- Absence of SQL Query (for some of them).
- Absence of Joins or Aggregate Functions.
- Slowness of Two Phase Commits (2PC) when data spread over multiple nodes.
- Any mass update.
To put the things in perspective, take a look at the projected revenue growth for various categories as per a study done by the 451 group
Connect to me on twitter @satya_paul
Check out my storyboard on www.fanffair.com - http://www.fanffair.com/storyboard/satyajitp2011